Technology Insights
7 Steps to Replacing a Message Broker in a Distributed System
By Abid Khan / November 22, 2022

In the initial stage of business development, startups tend to focus primarily on business features, and use tools and technologies which are capable of processing low to medium volumes of data. For this reason, leaders tend to ignore the complexity of data processing by the IT platform. This approach works fine until the business becomes mature and more complex. At this point organizations tend to need their tools to process larger volumes of data that are of many different varieties. When this happens, it greatly affects the overall throughput and performance of the platform. Organizations are forced to reevaluate and replace current technologies with others that provide better throughput, reliability, and observability.
At AppDirect, we have gone through a similar experience. From the beginning, our platform used RabbitMQ as the message broker. RabbitMQ performed well and met our requirements early on, processing the volume of data we required. However, as we started decomposing our monolith architecture into an event-driven microservice architecture, we saw a significant data volume increase in the platform. Platform performance suffered further when we started ingesting data from multiple new sources. RabbitMQ became unstable with this surge of data volume and required significant fine-tuning. These changes addressed the scale issue temporarily but it was not sufficient. With new microservices and new data sources being added, the overall platform latency kept increasing.
After this experience, our team began evaluating a few other message brokers. Our goal was to find one that would provide improved throughput, performance, and latency. We ended up selecting Kafka to replace our RabbitMQ layer. We all would agree that replacing an existing message broker is more challenging than selecting one, especially when we have multiple clusters and that use multiple cloud service providers. On top of that, not all clusters follow our regular release cycle. During such technological migration, we are supposed to ensure zero impact on business and zero impact on platform availability across clusters. These complex scenarios forced us to huddle up and come up with a concrete execution plan. Here I am not going to discuss the benchmarking we did before selecting Kafka over RabbitMQ and other message brokers. Instead, I am going to map out the process we followed to replace RabbitMQ with Kafka. I will take you through our execution plan and outline how our steps ensured zero impact on our platform’s availability.
1. Lean integration
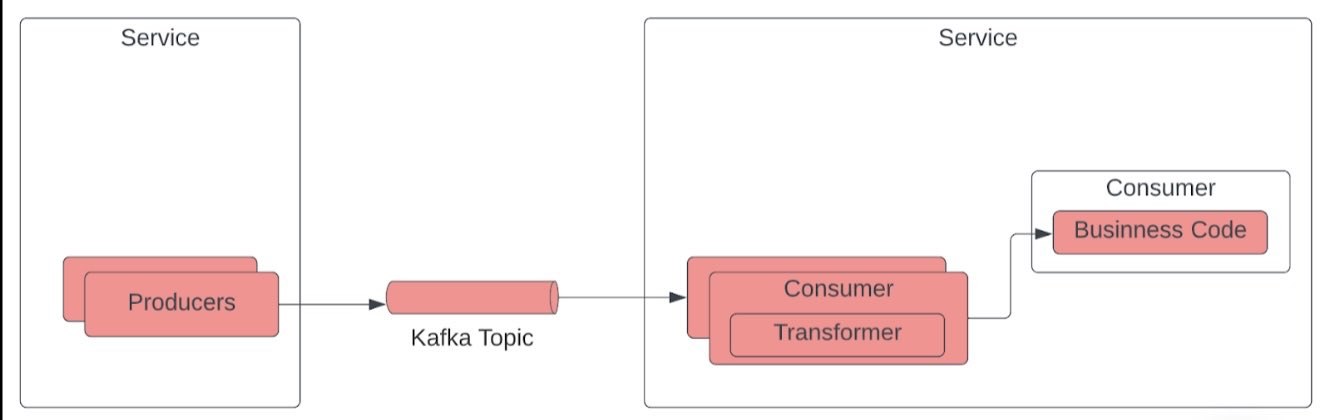
Engineers often end up writing business logic within the messaging integration context resulting in a “fat” listener. This prevents the reusability of the business logic for the new system. We started reviewing existing RabbitMQ integrations (read as listeners). The objective of this step was to move all business code to a business layer component and make the current listener thin and loosely coupled. After this activity, we had all business code moved to a new service reusable with new Kafka integration.

2. New Consumers
Next, we defined events, topics, and corresponding consumers. Events defined at this stage were similar to the RabbitMQ messages but differed in structure. To have seamless integration with business components, we had to build a transformation component. This new component converts events into business POJOs. After this activity, we have the consumer part of the integration along the event definition in place except for the producer of the events.

3. New producers
In this step, we implemented the required producers. All producers remain disabled with a feature flag. We performed end-to-end testing of the new pipeline and fixed bugs. After this step, we had two pipelines in place, with RabbitMQ processing live data, and Kafka in a disabled state.

4. Enable new pipeline partially
At this step, we started routing a small volume of events through the new Kafka pipeline. As our platform supports multi-tenancy, we enabled the pipeline for tenants having the least volume of data. We continued monitoring the performance of the new Kafka pipeline for a few weeks. After this step, most of the events were still being processed by RabbitMQ.

5. Route more volumes
Over the test period, as the pipeline matured and we started achieving our expected throughput, we started routing more volumes through the new kafka pipeline. We also continued monitoring the performance. As we increased the data volume in the Kafka pipeline, we gradually reduced volumes routed through RabbitMQ.

6. Enabling globally
As the new pipeline started working without issues for a few more sprints, we gradually enabled the new pipeline for all traffic. After this step, all events in the platform were routed through the new Kafka pipeline. And RabbitMQ pipeline remained idle with zero throughput. It remainss a fall-back mechanism and can be used to process events when the Kafka pipeline could not be used.

7. Deprecate the message broker
As the Kafka pipeline is enabled globally for all events, we started deprecating RabbitMQ integration from our platform. We did this in a phased manner to avoid any unwanted regressions.
One last thing
With Kafka in place, AppDirect is now better positioned to process large volumes of events. The additional tracing and observability system within the new message broker tool will guarantee high availability. As our business requirements keep increasing and the performance of our complex platform becomes even more critical, it is an important lesson to remember that technologies will need to continue to change to keep pace with our business growth. Maintaining a loose coupling between the business logic and your eventing system is key to success in performing the migration in a distributed system.
Related Articles

Technology Insights
Agentic Software Development Created New Friction Points—Where to Find Them, How to Fix Them
As AI accelerates software development, the bottleneck doesn't disappear. It moves. Mathew Spolin, AppDirect's SVP of Engineering and Technology, maps the four friction points that emerge when coding gets fast — and the practical solutions engineering and business leaders can act on today.By Mathew Spolin / AppDirect / June 3, 2026

Technology Insights
Cloud Forensics and the Digital Crime Scene: How Investigation, Prevention, and Resilience Have Evolved
The digital crime scene has moved to the cloud, where infrastructure is dynamic, data is distributed, identity often defines the perimeter, and AI is rapidly reshaping both breaches and defence. Here’s how cloud forensics has evolved, and why prevention, visibility, and forensic readiness now matter as much as investigation.By Denise Sarazin / AppDirect / May 21, 2026

Technology Insights
Navigating Technical Debt: How to Identify, Measure, and Manage it
Technical debt comes from taking shortcuts in software development that make systems harder to maintain, scale, and improve. Learn about the four categories of technical debt, what to watch for, how to measure it, and how to manage it before it derails your upcoming software and scaling efforts.By Mathew Spolin / AppDirect / April 27, 2026